I Built AI Agents Two Years Too Early
In 2023 I built basically every AI platform feature you've watched ship since — document collections, multi-model workflows, deployable bots. Here's why being early was the same as being wrong, and what I'm building now that the labs structurally can't eat.

TLDR: Back in 2023 I built LaraLlama — document collections you chat with, email/web ingestion, multi-model workflows, deployable bots and APIs. Two years later every major lab shipped the same shapes. I’m not claiming I invented anything; the ideas were obvious. What I got wrong was the layer (horizontal capability is exactly what model providers commoditize) and the substrate (the models couldn’t cash the checks the vision wrote). Now the substrate works, so I’m building the one thing the labs structurally won’t: software you own, on your own database, MIT licensed, shaped for small teams.
In 2023 I started building a product where you’d pour your documents, email, and web pages into collections, chat with them, wire workflows around them, and deploy the results as bots and APIs. I called it LaraLlama. If that sounds like every AI platform announcement of the last two years — yes. That’s the point of this story.
What LaraLlama was
LaraLlama was a Laravel app with a simple premise: bring all your unstructured data into one place, make it searchable with embeddings, and let people build things on top of it.
You could create document collections and chat with them. You could ingest email and web pages automatically. You could wire up multi-model workflows — chain different LLMs together for different tasks. And you could deploy the outputs as chatbots and APIs that other people could use.
I built it as a solo developer. 797 commits. 165 stars on GitHub. Real users trying it out. It worked — technically. The pieces connected. The architecture was sound.
But the answers were mediocre. The agents were unreliable. And no amount of product work fixes the substrate.
What happened next
Over the next two years, every major AI platform shipped the same shapes I’d been building:
- Document collections you can chat with? That’s Projects in Claude, GPTs with files in OpenAI, NotebookLM from Google.
- Email and web ingestion? Connectors are everywhere now.
- Multi-model workflows? Every platform has agent builders and orchestration tools.
- Deployable outputs? Claude Artifacts, custom GPTs, you name it.
I’m not claiming I invented any of this. The ideas were obvious — that’s why everyone converged on them. What I got wrong was the layer. I built horizontal capability, which is exactly the layer model providers always commoditize. And I built it on models that couldn’t cash the checks the vision wrote.
I archived the repo last year. It was the right call.
What’s different now
Two things changed.
The substrate works. Claude can actually reason about a 50-page proposal and produce something useful. Embeddings are good enough that RAG retrieval actually finds the right context. Tool use is reliable enough to build real workflows. The gap between “demo” and “production” collapsed.
I’m not building on the layer the labs eat. The platforms will keep shipping incredible capability layers — better models, more context, cheaper inference. That’s great. I want to build on top of that, not compete with it. I’m building the layer they structurally won’t: software you own, on your own database, MIT licensed, shaped for small teams instead of everyone.
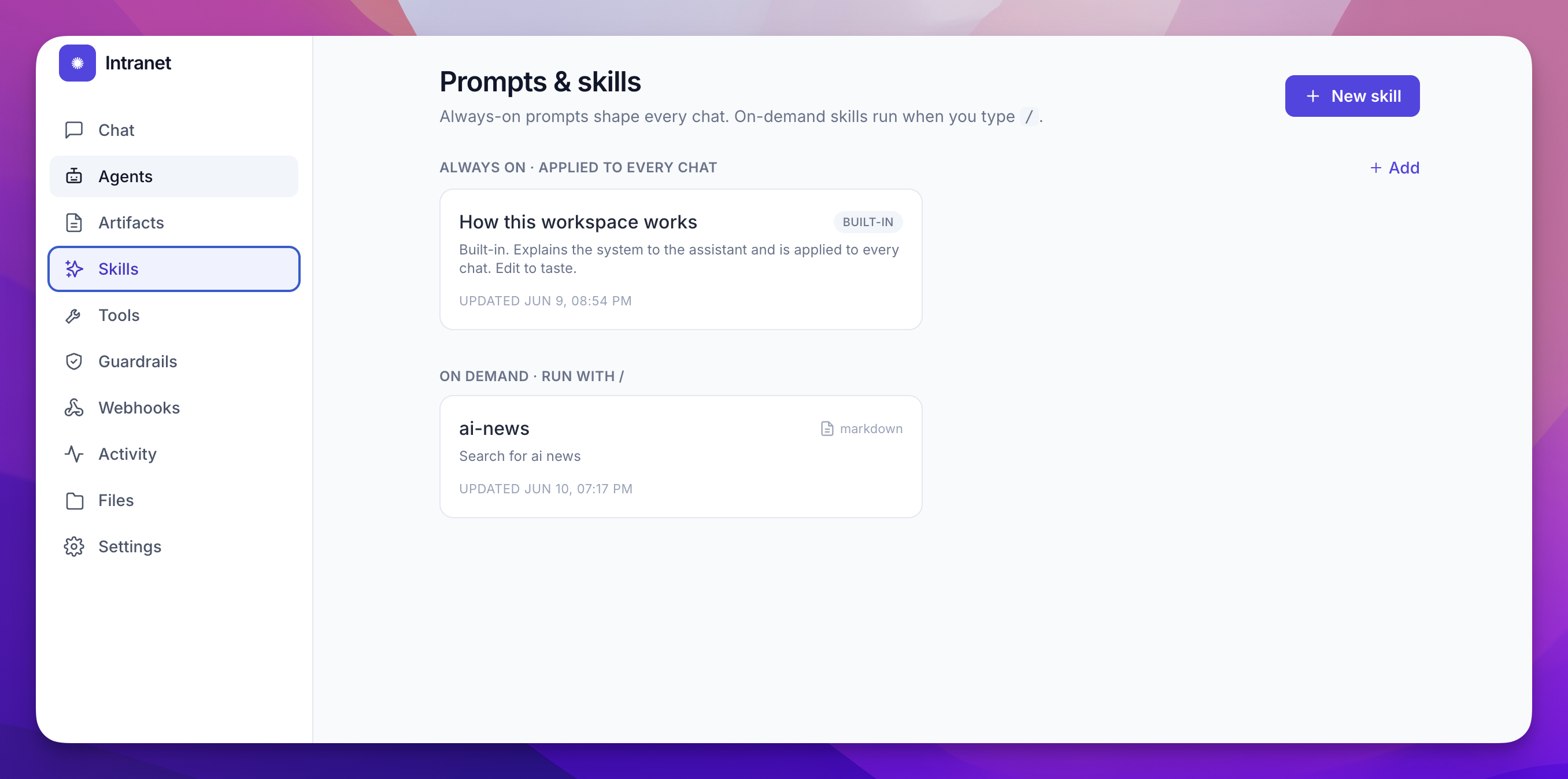
What Intranet In A Box is
Intranet In A Box is an open-source AI intranet for small teams. Your team’s AI, on your own database.
The whole stack:
- React SPA, MIT licensed
- Supabase for everything: Postgres, auth, realtime, storage, edge functions
- Row-level security is the boundary — the browser only ever holds the anon key
- PDFs index into pgvector, embedded free at the edge
- Agents, webhooks, scheduled jobs, even the AI’s tools: rows in tables, not deployments
- The Anthropic key never leaves the server
No per-seat pricing because there’s no vendor in the middle. Your data sits in your Postgres. Stop using it tomorrow and you keep everything.
Here’s what the day-one workflow looks like for a small agency:
- Upload your past proposals and your rate card. PDFs index automatically.
- Ask: “Draft a proposal for a Shopify build for a 10-person retailer. Price it like the Henderson project.”
- It searches your documents and drafts in your format with your pricing.
- Say “make that an artifact” — you get a link to send the client. No login on their end.
The part that matters: next month’s proposal is drafted with this month’s as context. The system compounds — it gets better the more your team uses it.
Building in the open
I’m building this in public, shipping and posting weekly. The repo is MIT licensed and live:
https://github.com/alnutile/supabase-as-a-service
If you’re a developer, freelancer, or agency tech lead — star the repo, fork it, deploy it. It’s yours.
If you run a small team and this sounds like the thing you’ve been duct-taping together with personal ChatGPT accounts — subscribe here. I’ll be showing what’s possible, one feature at a time, every week.
The labs will keep shipping incredible capability layers. I’m building the layer they structurally can’t: the one you own.