More Models, More Prompts: RFP Analysis & Structured Output
Testing local LLMs on real business extraction tasks
Quick context: Most AI benchmarks test whether models on tests that do not always relate to everyday business challenges. I am going to be testing whether a model running on your laptop or on-premise desktop can actually help a business parse an RFP, extract data from invoices, or draft a professional email. The stuff you’d actually pay someone to do.
My Take
This update adds RFP analysis and structured output tests. The RFP stuff is interesting because I ran into a case where the model did everything right but still failed. More on that below.
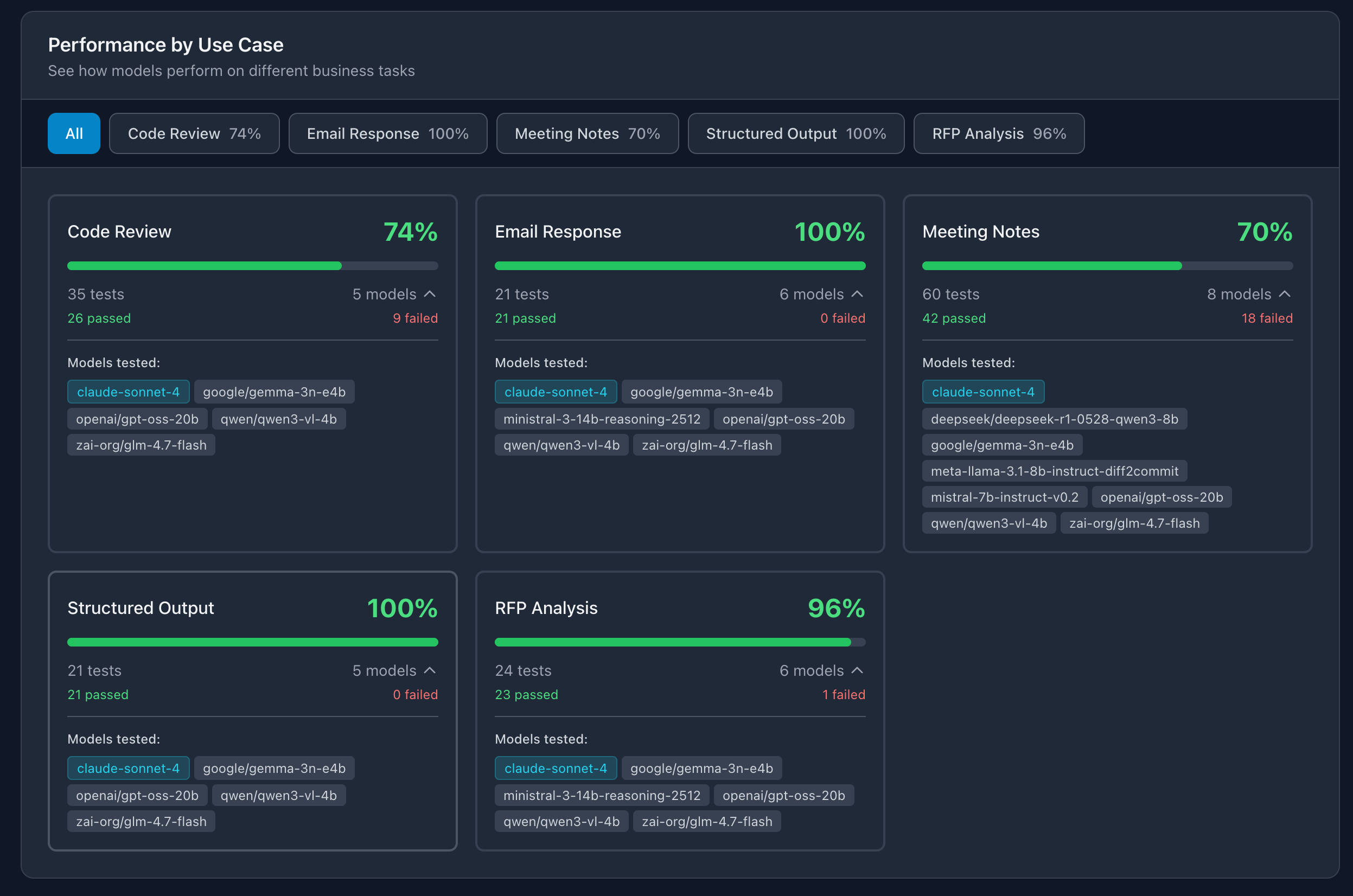
I’m also including more models now ministral-3-14b-reasoning-2512 and zai-org/glm-4.7-flash. The goal is to have every model run every test so the comparisons are fair. Still working on that.
Below are some of my notes then I will point out the ai notes after that.
While running the RFP tests, qwen/qwen3-vl-4b failed one. Scored 0.88, just under the threshold. But it did the extraction part fine. Got all 5 requirements right:
Multiple data sources (SAP, ProjectManager.io, Excel)
Two user types (public vs admin)
WCAG 2.1 AA accessibility
FedRAMP hosting
$200K budget ceiling
The failure was in the clarifying questions. The rubric - basically the answer key I wrote for what a good response should include - expected questions about data refresh frequency, existing APIs vs manual exports, number of dashboards. The model asked about integration details, authentication, data volume instead. Related stuff, just not the exact questions.
Here’s the thing that surprised me most: Claude graded it 0.7. GPT-4o-mini gave it 1.0. Same exact answer. This is why single-judge evaluations are sketchy - one model’s “pretty good” is another’s “needs work.” Using three judges doesn’t solve this, but it surfaces the disagreement.
So the model gave a reasonable answer. It just didn’t match the rubric exactly. That’s the tricky part with LLM evaluation - how strict do you want to be? I updated the prompt to be clearer and we’ll see.
Structured Output Tests
I added structured output tests because that’s what many businesses actually need.
NOTE: I need to push these prompts more and setup better test data so there will be some updates there.
What’s Next
-
Continue running all models through every test category
-
Adding more complex structured JSON output cases the ones right now are kind of weak.
-
Code review tests are in progress
-
Might revisit some earlier prompts based on what I learned from the qwen failure
-
Keeping up on the models as seen here https://lmstudio.ai/models, https://huggingface.co/ etc
Let me know in the comments if there are specific business tasks you’d want to see tested.
Ai Notes
Generated with AI:
Judges: Each response gets evaluated by Claude Sonnet 4, GPT-4o-mini, and Grok. Three opinions instead of one.
Models tested: zai-org/glm-4.7-flash, openai/gpt-oss-20b, qwen/qwen3-vl-4b, google/gemma-3n-e4b, deepseek/deepseek-r1-0528-qwen3-8b, meta-llama-3.1-8b-instruct-diff2commit, mistral-7b-instruct-v0.2, ministral-3-14b-reasoning-2512. Claude Sonnet 4 as cloud baseline.
Test categories: Meeting Notes (task extraction), Email Response (tone + completeness), RFP Analysis (requirements + questions), Code Review (bugs + feedback), Structured Output (valid JSON + correct types).
Why three judges? The qwen RFP example shows why. Claude scored it 0.7, GPT-4o-mini gave 1.0. Same response, different interpretations. Using multiple judges surfaces these disagreements instead of hiding them.
Dashboard updates: Added expandable model lists under each use case card so you can see exactly which models were tested where. Claude models show up in cyan to make the cloud baseline easy to spot.