Local Ai Testing for Business Use Cases: New model GLM-4.7 and Email Test in the mix
Fun updates, better prompts, better results
Check out the results at 👉 https://localaibench.com/
[
](https://substackcdn.com/image/fetch/$s_!TgIf!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5d1e3437-6464-4736-9551-577cd0456219_2528x1664.png) Ok it does not look this cool 🙂
My Take
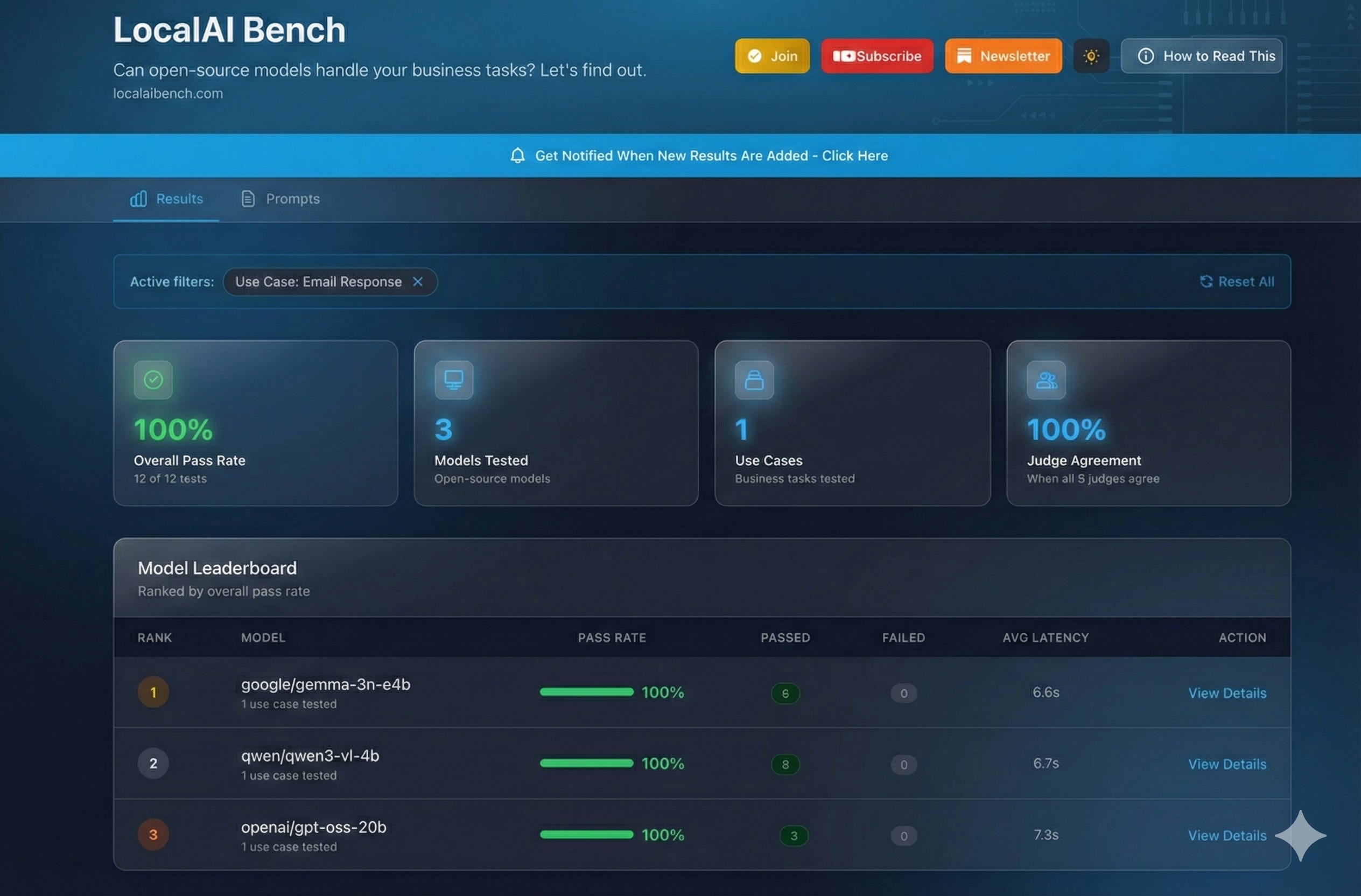
My latest run includes some more business workflows. One is about email responses. And one is going to be about RFP analysis. So you’ll see some data there.
I’m still trying to get the quality of the prompts right so that the results show the model’s abilities, not the lack of prompt quality. You’ll see I tweaked the prompts a bit, and now these models are scoring 100%. So it’s something to really consider. It makes me think about going back and rerunning a lot of these tests. But right now, this is what I got.
[
{kind=link}
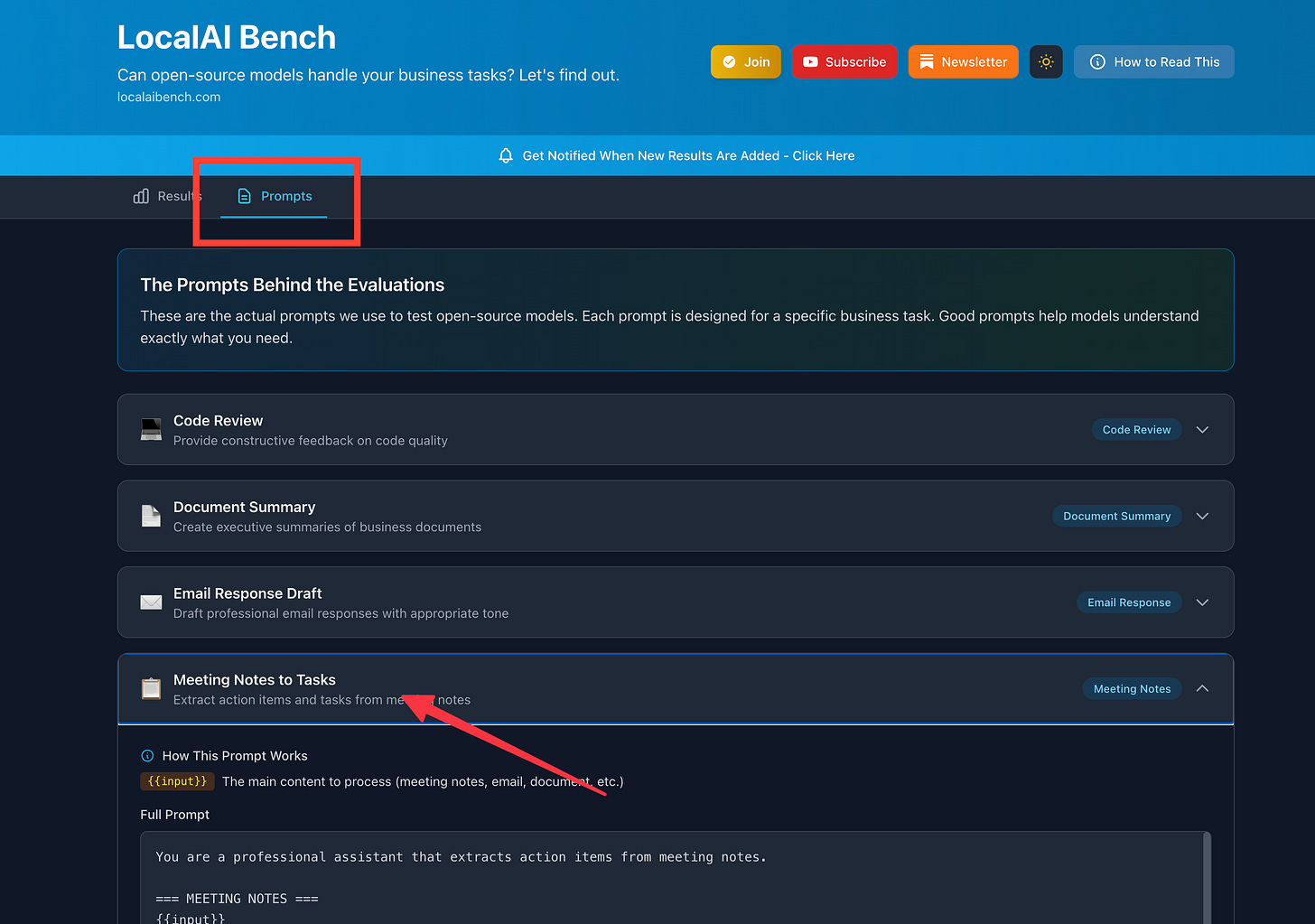
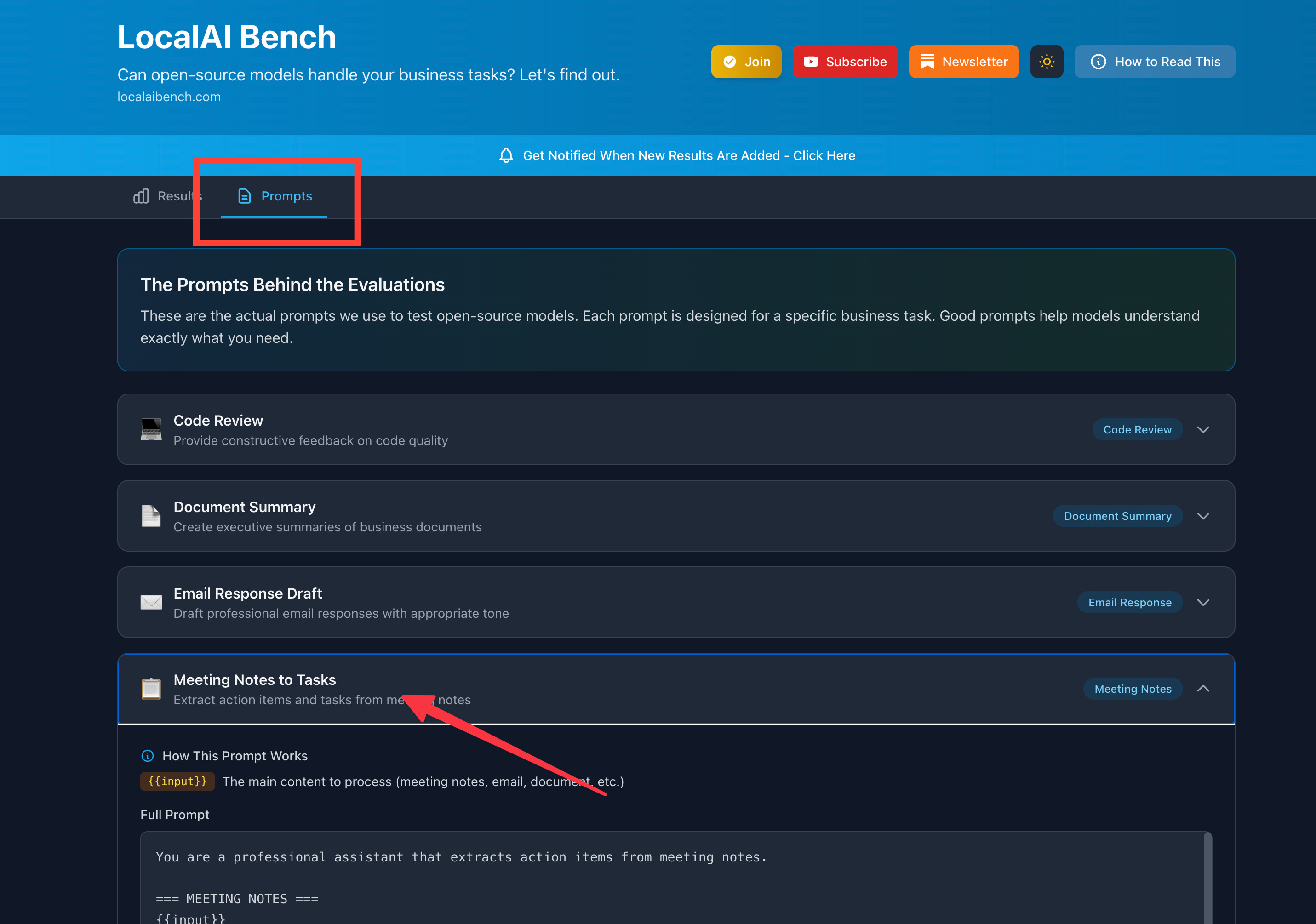
You’ll see too, I started to include GLM-4.7 Flash. I’m excited to see how well this is performing. I’m going to make sure all these models run each one of these tests.
[
{kind=link}
[
{kind=link}
From here, I’m going to get into structured output tests because that’s really important. And code review tests, because some people want to do that. There are some other tests in the works too, like doc summaries and comparisons. But I’ve got to make sure the data—the mock data—is good and the prompts are good.
Please comment with ideas or have comments on how I could do this better, since it is a work in progress.
Hope you’re enjoying it so far. Below is an AI-written analysis of the results.
Below is the Ai TLDR 👇
Analysis of Current Results
What’s Being Tested
Three business workflows are now in the evaluation suite:
Email Response Drafting - Handling client concerns, HR communications, and difficult customer situations
Meeting Notes to Tasks - Extracting action items with owners, deadlines, and priorities
RFP Analysis - (Coming soon with refined test data)
Current Model Performance
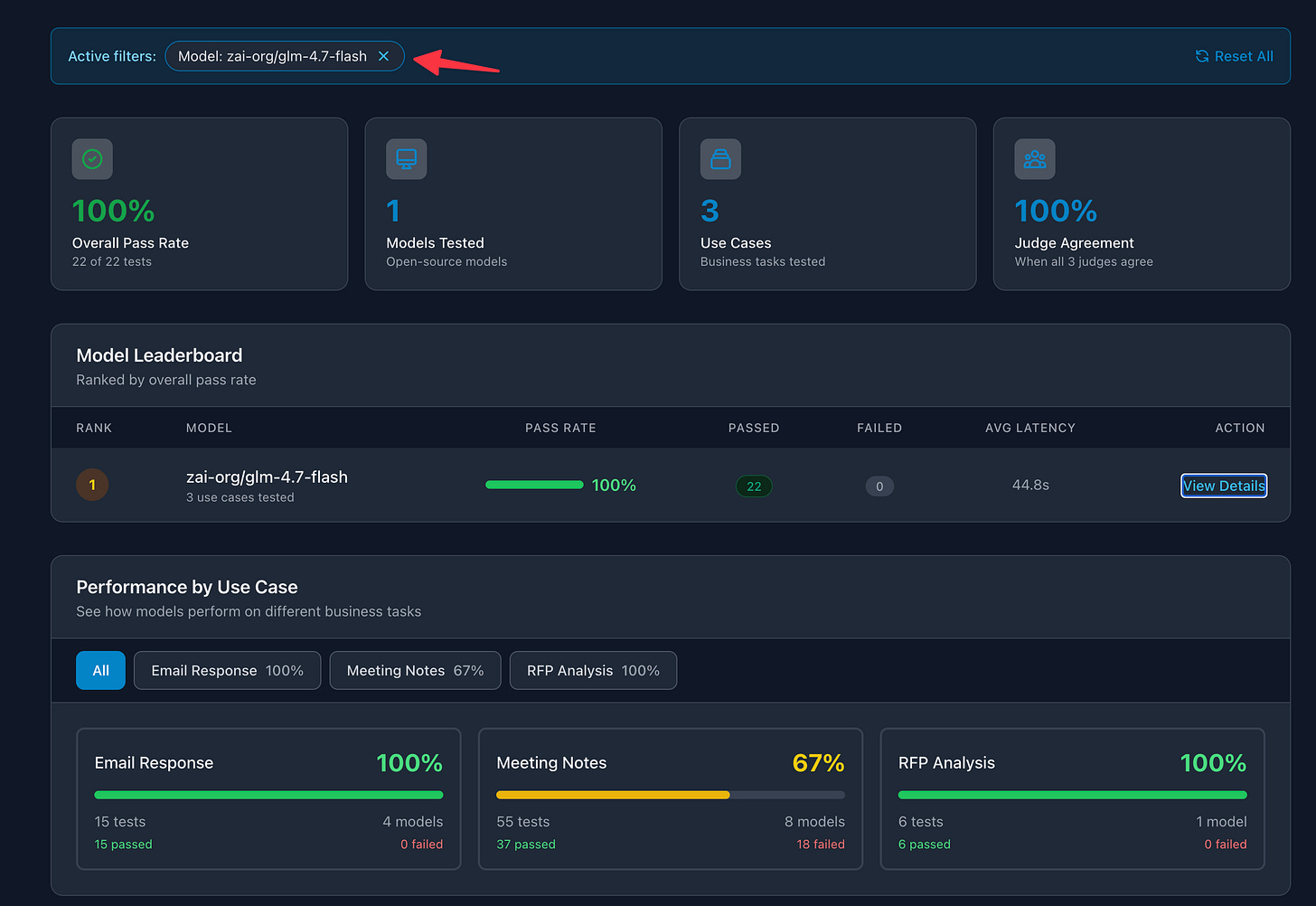
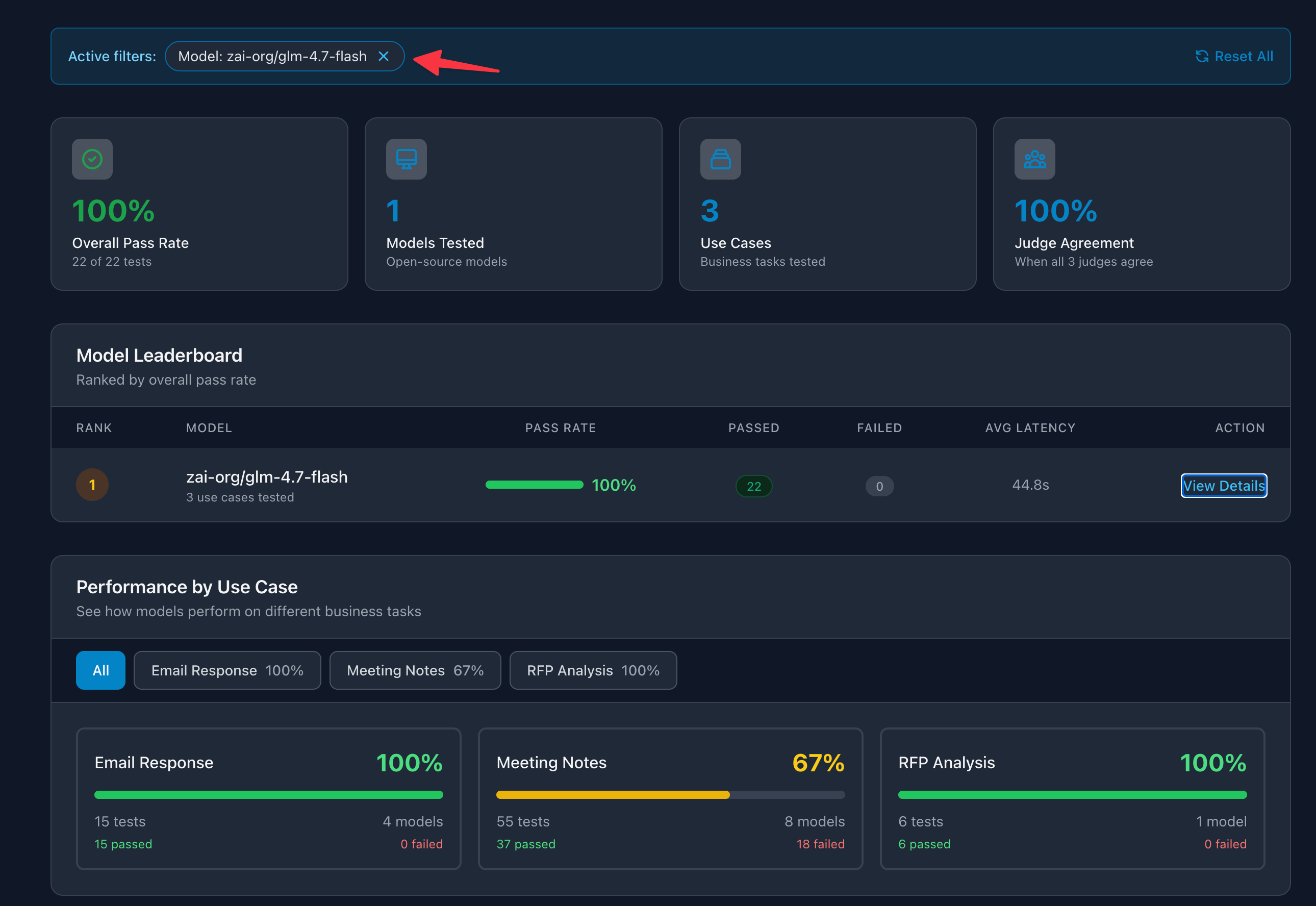
GLM-4.7 Flash (the newest addition):
Email responses: 3/3 tests passed (100%)
Meeting notes extraction: 5/5 tests passed (100%)
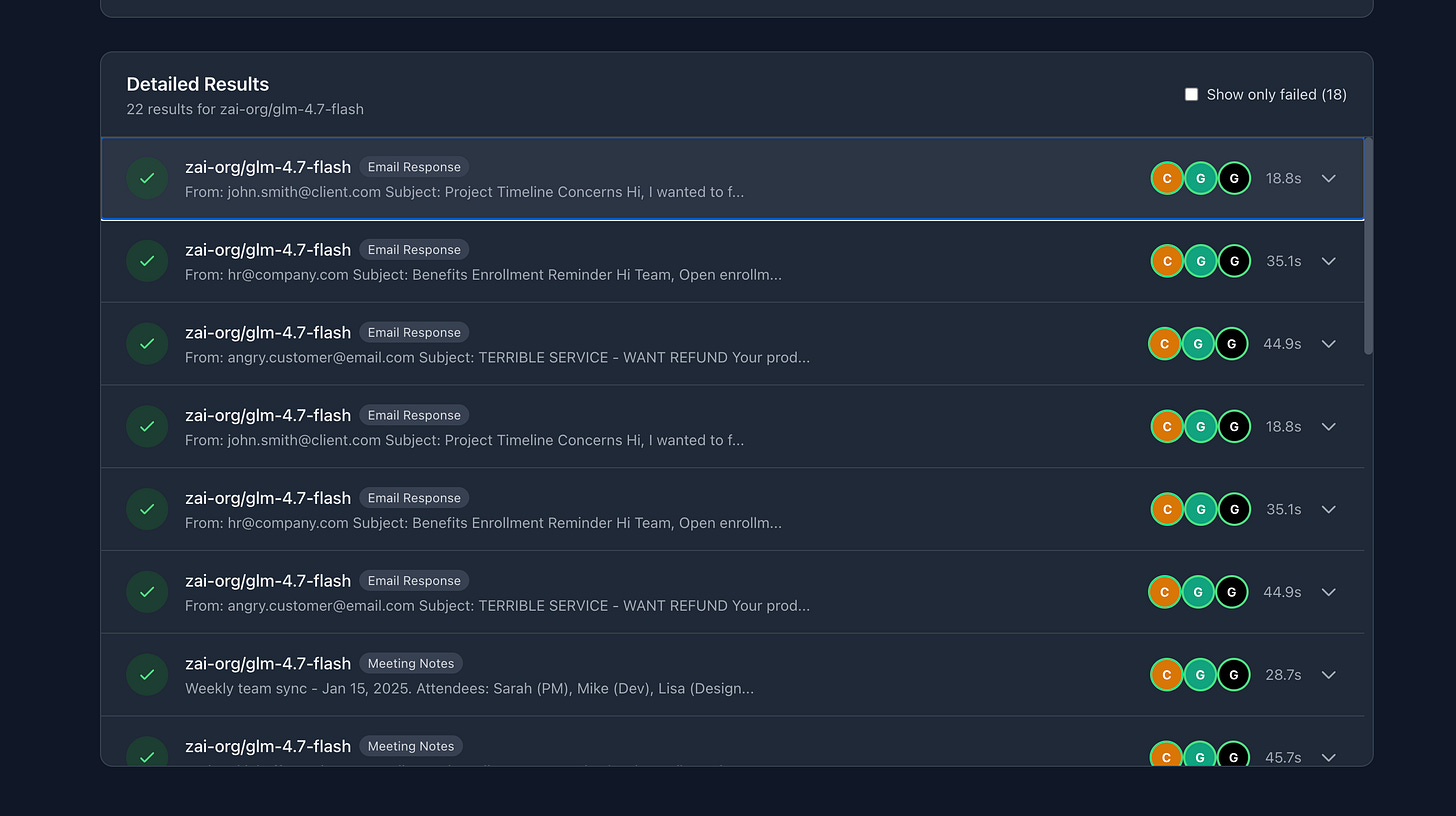
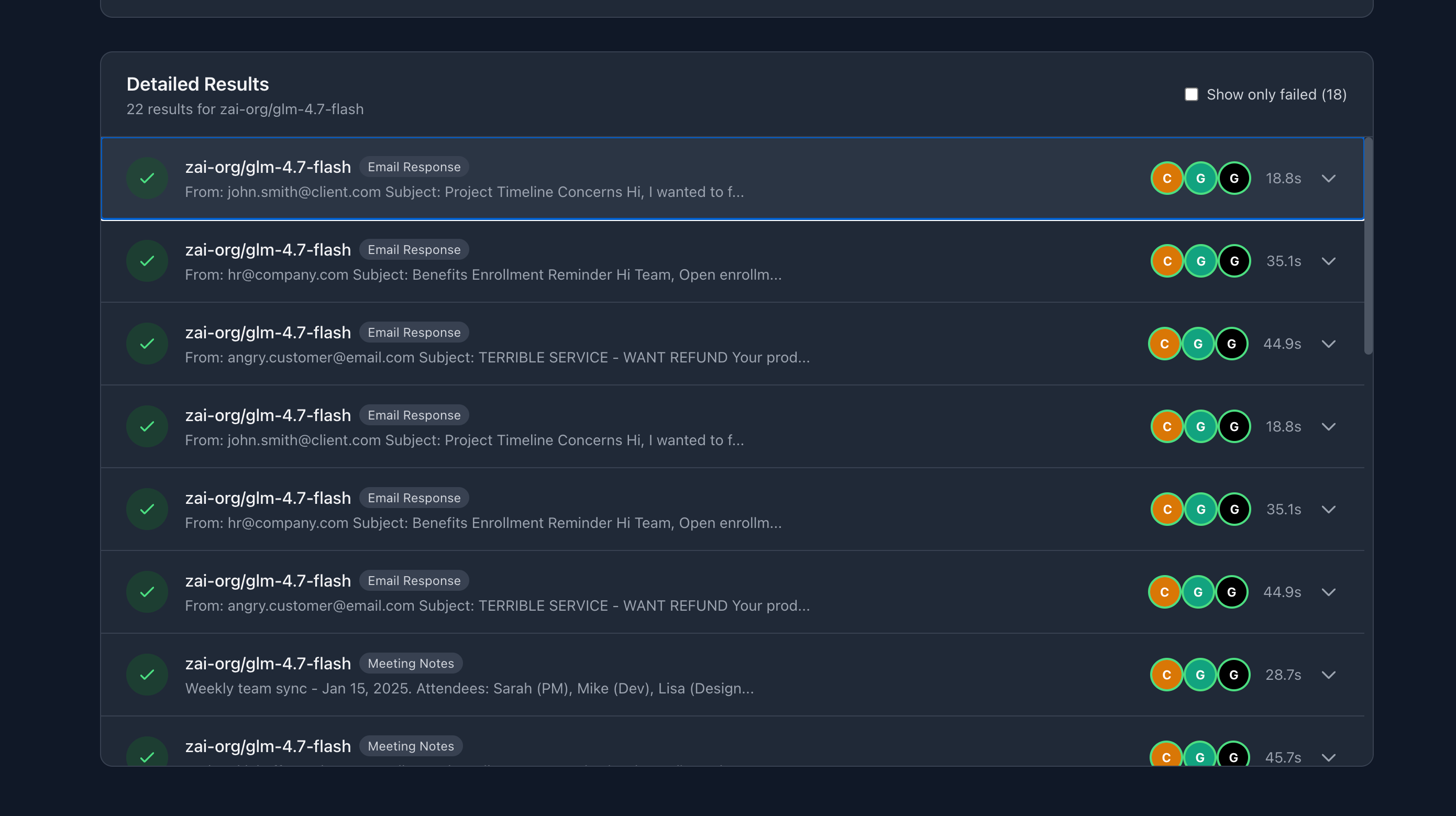
All three judges (Claude Sonnet 4, GPT-4o Mini, Grok 4.1 Fast) agreed on the passing results.
The Prompt Quality Factor
The jump from ~60% to 100% pass rates came from prompt refinements, not model changes. Key additions included:
Explicit checklists for models to verify before responding (e.g., “Did you include the actual sender name?”)
Clearer structure for edge cases like qualifying life events in HR emails
Specific formatting requirements for task extraction
This is worth noting: a model scoring poorly might just need a better prompt. The evaluation system tests both together, so isolating model capability from prompt quality takes iteration.
What’s Next
Running all models through each workflow for comparable data
Adding structured output tests (JSON responses, schema adherence)
Code review evaluations
Document summarization with better mock data
Technical Notes
Switched to Grok as a judge due to Gemini API reliability issues (503 errors)
Using LM Studio for local model inference
Results viewable on the dashboard at [your link]